System Integration and Communication
The process through which system components communicate and share information through compatible interfaces and messages.
Database Integration
Using a database is used as the primary form of sharing information between components of the system. Using database integration, system components communicate with each other indirectly through a database; one component may write to the database, and another component reads from it.
Using a database as the primary form of sharing information runs into significant problems as the system grows larger and more complex. Here are some key problems:
- External Exposure to Internal Data Models - the internal implementation of database models is exposed and visible to external users. If there are schema changes, this could easily break the way services access the database. Since there is no external interface, all services would need to understand the data structures and schemas to use the database.
- Tight Coupling - each component is tied to the specific platform and implementation of the database. If the database platform needs to be changed, each of the services will need to make corresponding code changes.
- Lack of Security and Controls - by exposing the data models externally, the system is unable to fully control how data structures are accessed, adding security and authorization problems.
- Low Cohesion - the same logic to access the data is repeated in many services, and different versions of this logic may arise.
- Scalability problems - scaling is now only possible through the database.
- Asynchronous/Orchestration problems - if a service makes a transaction to the database, it is difficult for other components to know when the transaction was reflected in the database resulting in possible race conditions.
Thus databases should be avoided as the primary form of integration system. Instead access should be controlled through services for both external clients and other internal clients.
REST
Representational State Transfer (REST) is an architectural style that provides a design of communication between computers on a network.
An API that follows the REST architectural style is called a REST API (RESTFul API) and can be used for system integration. The architecture focuses on scalability, interfaces, loose coupling, and encapsulation. Its standards and constraints are:
- Client-server pattern - client and server should be separate components, developed independently, and communicate through an interface. This improves portability across different platforms and separates the interface (client-side) from logic and data (server-side).
- Resource Representation - data and content should be represented as resources. A REST server is responsible for managing these resources and allows clients to access and modify these resources through operations.
- Interface Uniformity - service interfaces should support the same set of operations. Allows for loose coupling, where services and clients can be developed separately without impacting each other. The downside is that this uniformity forces all clients and services on the same set of operations, and there cannot be specialized methods.
- Statelessness - operations are stateless, such that each request should incllude all the required information needed to process the request. Requests cannot assume ore require the server to have any stored context or data. Rather, the client is responsible for managing and storing all of the session's data and state. That is the client does not need to know what state the server is in and vice versa. The overhead here is that there may be repeating data in requests.
The opposite of statelessness is statefulness where the client request uses context stored on the server.
HTTP
HTTP is an example of a protocol that follows REST principles.
- HTTP requests and responses have a client-server pattern (e.g. clients such as web browsers send requests to web servers). Both client-side and server-side components can be developed separately and can operate on different technology stacks.
- HTTP treats content such as HTML, CSS, Javascript, images, and video files as server side resources. Each file is accessed as a resource with a unique URL.
- HTTP operations follow a uniform interface because they use the same request methods. The four main HTTP methods used to send and receive requests are
POST, GET, PUT, and DELETEwhich correspond toCRUD (create, read, update, delete)operations.
| HTTP Method | URL Path | Description |
|---|---|---|
| POST | /courses |
Create a new course |
| GET | /courses/{course_id} |
Get an existing course |
| GET | /courses/ |
Get all courses |
| PUT | /courses/{course_id} |
Updated an existing course |
| DELETE | /courses/{course_id} |
Delete an existing course |
- HTTP requests are stateless - each of the CRUD operations contain all of the information needed to process and form a response. The client manages all of the information and does not assume that the server has any stored context.
A system can be RESTful without using HTTP, and likewise HTTP communication does not need to follow REST principles.
RPC
Remote Procedure Call (RPC) is a form of inter-process communication in which a process invokes a local call that causes a routine to execute in another process that is running on a remote machine over a network. A call (procedure call, function call, or subroutine call) is the invoking of a function.
Popular RPC frameworks include gRPC, Thrift, and JSON RPC.
RPC Frameworks use stubs - these are compiled with the client and server code to communicate between the server and client.
- A client stub receives the local call from the client and is responsible for the conversion of parameters and data. It also performs serialization by transforming the request into a transmittable form that can be sent over a network.
- A server stub is responsible for the deserialization of the transmitted request and the deconversion of the parameters and data into a remote call to the server. It is also responsible for the conversion and serialization of the response back to the client.
An RPC Runtime is the software that manages the transmission of the request and responses between client and server. This runtime is typically built on top of the networking protocols and is responsible for retransmission and encryption.

Interface Definition Language (IDL)
Defines how software components written in different languages can communicate with one another through a common interface that is language-independent.
For example, gRPC provides an IDL called Protocol Buffers (or "protobug") and defines messages and RPC methods that are language agnostic.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 | |
Benefits of RPC
- Abstraction - applications and developers do not need to understand the inter-process network call mechanism
- RPC Frameworks - provide stubs in high-level languages, allowing applications to integrate with minimal efforts
- Method calls do not need to conform to a standard interface and can be highly optimized
- Allows for serialization in binary and customized formats, which typically means tight data packing and smaller packet payloads
There just is no standardization - one downside compared to REST.
REST vs. RPC
Generally integration with external clients use REST protocol (e.g. RESTful HTTP) but integration behind the reverse proxy for internal components uses an RPC framework. This pattern is common because REST calls have a standard interface so that most client-side applications can be developed without being tied to specific technologies. However RPCs are usually more performant than REST calls, and a system where a single RPC framework is enforced can achieve a more efficient integration.
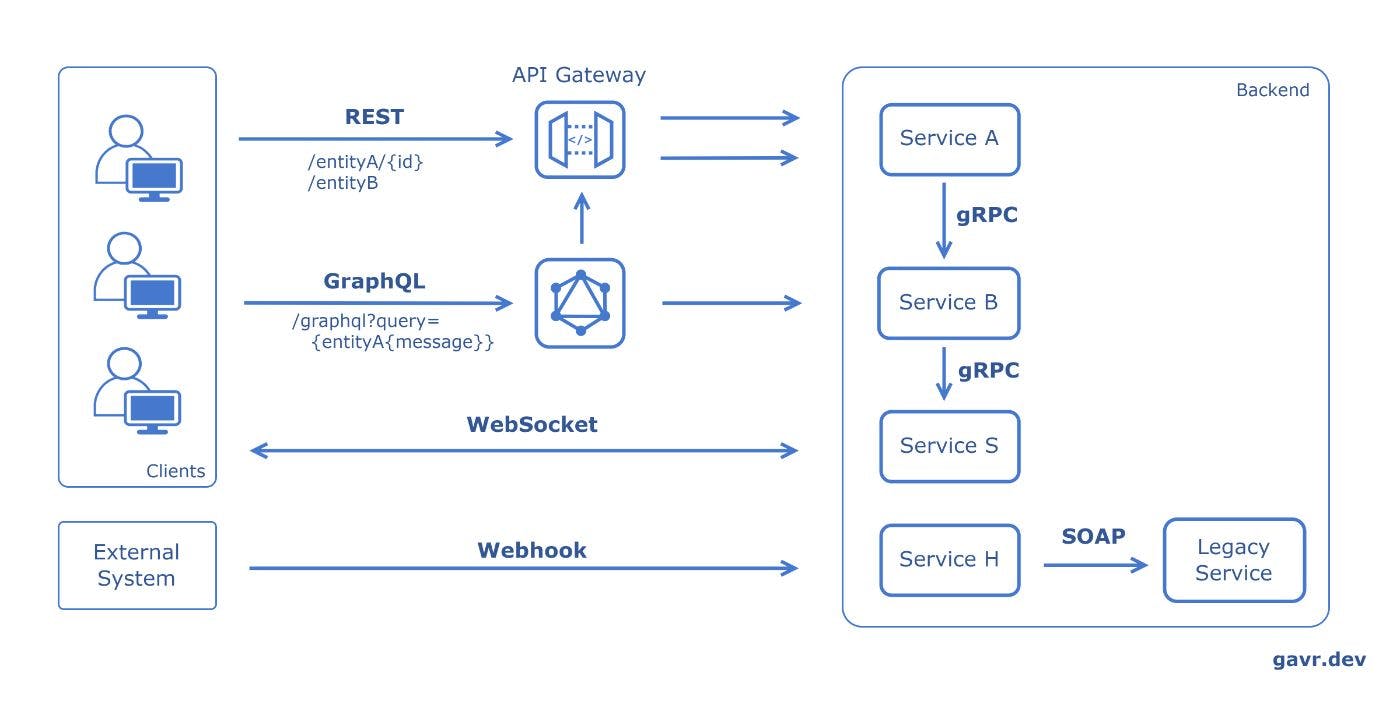
REST APIs are centered around resources while RPC APIs are centered around actions.
| REST Method + Resource | RPC Action |
|---|---|
POST /courses |
createNewCourse() |
GET /courses/{course_id} |
getCourse() |
PUT /course/{course_id} |
updateCourse() |
DELETE /course/{course_id} |
deleteCourse() |
RPC frameworks also add another application layer of protocol on top of existing Internet protocols unlike REST (which uses HTTP). The result is that an RPC framework is tightly coupled with its underlying technology stack, whereas REST implementations are more agnostic of the technology stack.
A summary of the comparisons between REST and RPC:
| REST | RPC |
|---|---|
| Resources representation of data | Action based view of data |
| Human readable message formats (e.g. JSON) | Binary message format (e.g. protocol buffers) |
| Usually uses the HTTP 1.1 protocol | Customized network communication protocols or not widely used protocols |
| Lower throughput performance and high latency | Higher throughput performance and low latency |
| Usually uses the standard HTTP methods, no need for additional libraries or code | Custom developer defined methods that use stubds and an RPC runtime |
| Self-documenting | Separate documentation |
| Stateless | Stateless |
| Communication through HTTP action verbs (CRUD) | Communication is performed by invoking method calls and specifying params |
More On Serialization
Naive approach to serialization is to use language specific frameworks like Python's pickle, Marshal for Ruby, Serializable for Java etc. However these are locked to a single language and deserialize data into arbitrary classes which lead to security vulnerabilities. Also there is not data versioning.
Some common standardized encoding formats used are:
| Feature | JSON | Protocol Buffers / Thrift | Avro | Parquet |
|---|---|---|---|---|
| Data Representation | Human-readable | Binary | Binary | Binary |
| Schema Support | No | Yes | Yes | Yes |
| Schema Evolution Support | No | Limited | Yes | Limited |
| Efficiency | Less efficient due to text format | Highly efficient binary format | Efficient binary format | Highly efficient for analytics |
| Programming Language Support | Widely supported | Supports multiple languages | Supports multiple languages | Limited (primarily for analytics) |
| Tagging of Fields | No | Yes | No | No |
| Readability | Human-readable | Not human-readable | Not human-readable | Not human-readable |
| Common Use Cases | Interchange between systems | Efficient data transmission between systems | Data interchange, message serialization | Efficient storage and querying for analytics |
| Examples | Web APIs, configuration files | Google APIs, Apache Thrift | Apache Kafka, Apache Avro, Hadoop ecosystem | Apache Hadoop, Apache Spark |
Realtime Updates
When there is a need to provide real time updates from a database or server back to a client (e.g. in a chat app, ride sharing app, and notification services) there are a few options:
-
Long Polling
- Description
- make a typical HTTP request to the server, and if the server does not have newdata it keeps the request open, and eventually reponds once new dta is present.
- once new data is recieved, the client issues another long polling request
- connection timeouts also results in client sending another request
- Pros:
- Easy to implement
- Cons:
- one directional, and can cause excess load by constantly recreating HTTP connections
- possible race condition of multiple requests
- Description
-
Websockets
- Description
- fully bidirectional communication channel between clients and servers
- websockets are registered to a port which means it can have ~65k active connections
- Pros:
- bidirectional communication in realtime
- lower network overhead as headers are only sent once
- Cons:
- less support for older browsers / clients
- may be complex for infrequent data changes
-
Server Sent Events
- Description
- one way connection from servers to clients, cliet-side code registers for events from the server
- Pros:
- persistent HTTP connection (unlike long polling)
- connection restablished automatically upon failure (unlike websockets)
- Cons:
- single directional communication
- a lot of concurrent connections can add load on server