CAP Theorem
A theoretical framework to understand tradeoffs in data intensive distributed systems. It states that a distributed system can only have two of the three characteristics of consistency, availability, and partition tolerance.
- Consistency - also known as
CAP consistency, strong consistency, or strict consistency- means that simultaneous read requests at different nodes always return the same data. Additionally all operations "appear" atomic i.e. when a write transaction has been completed, all read requests from all clients must reflect the changes from that write transaction. Different from ACID Consistency - Availability - every request to the system at any node recieves a response
- Partition Tolerance - when a network's nodes are split into groups that cannot communicate with each other, the system continues to operate despite the communication breakdown.
For distributed system partition tolerance is a necessary characteristic - so the choice is usually between consistency and availability. Hence effectively the theorem states that during a network partition, a distributed system can provide either availability or consistency.
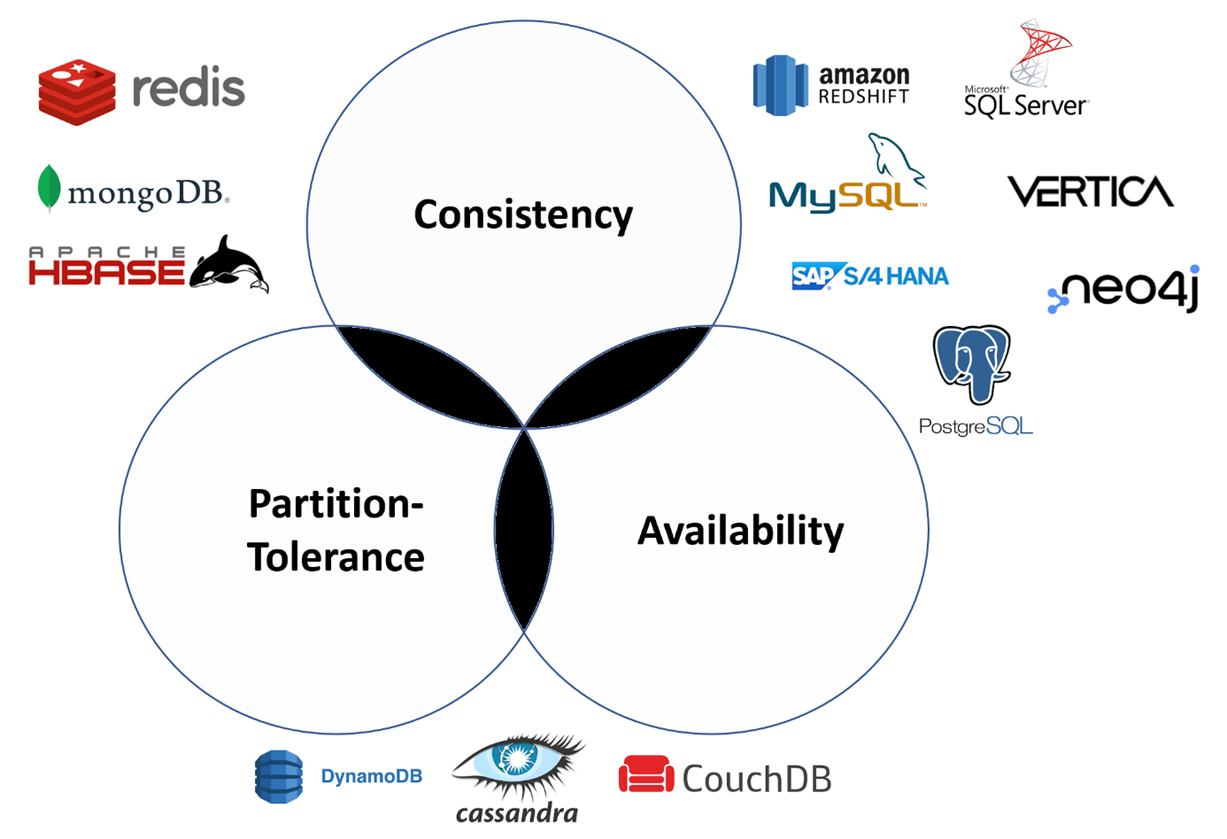
- CP System: CP means the system exhibits consistency and partition tolerance at the cost of availability. During a network partition, a CP system either rejects write requests or shuts down the inconsistent nodes. Both scenarios reduce availability but provide consistency.
- AP System: AP means that the system exhibits availability, and partition tolerance at the cost of consistency. During a network partition, an AP database continues to process write requests and allows inconsistent nodes to operate, but the inconsistent nodes may have stale data. Hence the system needs to resync all nodes when the network partition is repaired.
- CA System: CA means the system exhibits availability and consistency at the cost of partition tolerance. This is not useful for distributed systems as they all suffer from network partitions.
However in practice the boundaries are not so hard - for example distributed systems rarely have 100% availability, but instead availability is denoted by the percent of uptime (e.g. four or five 9's).