Trees
Trees are a non-linear data structure that allow us to implement a range of agorithms that are faster than using linear data structures like array-based lists or linked lists. Trees also provide a natural organizationof data, and have become ubiquitous structures in file systems, GUIs, databses etc.
Trees are hierarchical representation of a set of nodes storing elements such that the nodes have a parent-child relationship with the following definitions and properties:
- root - top node of a tree
- parent - except for the root node, all nodes in a tree have a parent
- children - nodes in a tree may have zero or more children
- depth \(d_p\) - for a position
pof a node in a treeT, the depth ofpis the number of ancestors ofp, excludingpitself. (but it includes the root node) - e.g. if
pis the root, then its depth is 0, otherwise it is1 + depth of the parent - height \(h_p\) - defined from the leaf of the tree, defined recursively
- e.g. if
pis the leaf of a tree, its height is 0, otherwise it is1 + max(height of children) - the height of a non-empty tree T is equal to the maximum of the depths of its leaf positions
In a tree, each node of the tree apart from the root node has a unique parent node, and every node with a parent is a child node.
Trees can be empty (i.e. don't even have a root node) which allows for recursive definitions such that:
- a tree
Tis either empty or consists of a root noder - root node
rhas a set of set of subtrees whose roots are the children ofr
Ordered Trees
A tree is ordered if there is a meaningful linear order among the children of each node - i.e. we can identify the children of a node as being the first, second, third and so on. This is usually visualized by arranng siblings left to right, according to their order.
Tree Abstract Base Class
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 | |
Linked Structure for General Trees
A natural way to represent a tree is through a linked structure, with nodes that maintain references to the elment stores at a position p and to the nodes associated with the children and parent of p.
For a general tree, there is no limit on the number of children that a node may have. A natural way to realize a general tree T as a linked structure is to have each node store a single container of references to its children.
The tree itself also maintainsan instance variable storing a reference to the root node, and a variable called size that represents the overall number of nodes of T.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 | |
Binary Trees
A binary tree is an ordered tree with the following properties:
- Every node has at most two children
- Each child node is labeled as being either a left child or a right child
- A left child precedes a right child in the order of children of the node
The subtree rooted at the left child is called a left subtree and rooted at the right a right subtree.
Recursive Definitions of a Binary Search Tree
A binary tree is either empty or consists of:
- a node
r, called the root ofT, that stores an element - a binary tree (possibly empty), called the left subtree of
T - a binary tree (possibly empty), called the right subtree of
T
Types
Proper/Full
A Full or Proper binary search tree is one where each node has either zero or two children. Therefore internal parent nodes always have exactly two children.
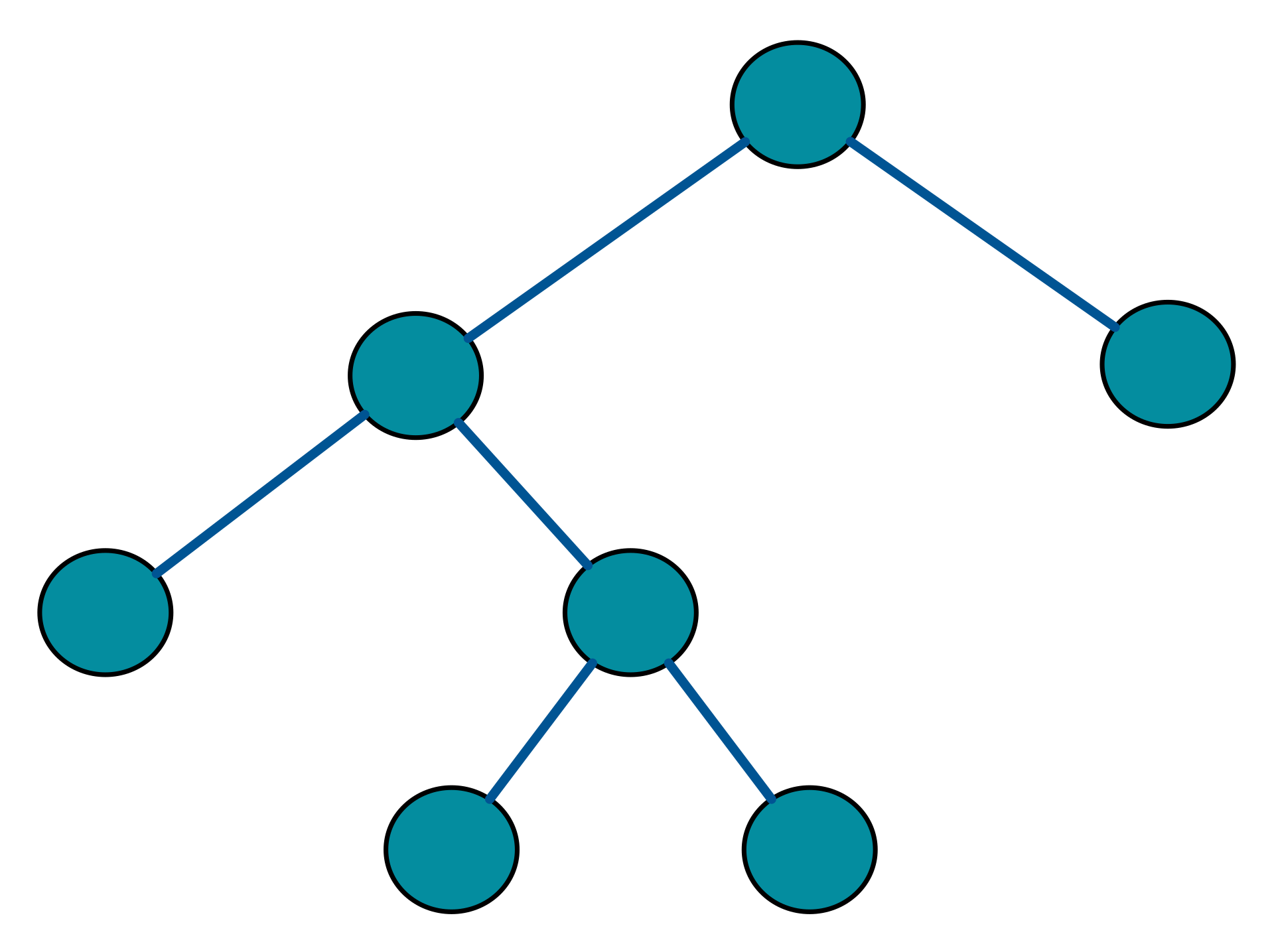
An example is expression trees that capture the arithmetic expression e.g. (((3+1)x3)/((9-5)+2) as shown below:
1 2 3 4 5 6 7 8 | |
Perfect
All interior nodes have two children and all leaves have the same depth or same level. A perfect binary tree is also a full binary tree.
Complete
All levels of the binary tree (0, 1, 2, ..., h -1) have maximum number of nodes possible (i.e. \(2^i\) nodes for \(i \leq i \leq h-1\)) and the remaining nodes at level h reside in the leftmost possible positions at that level.
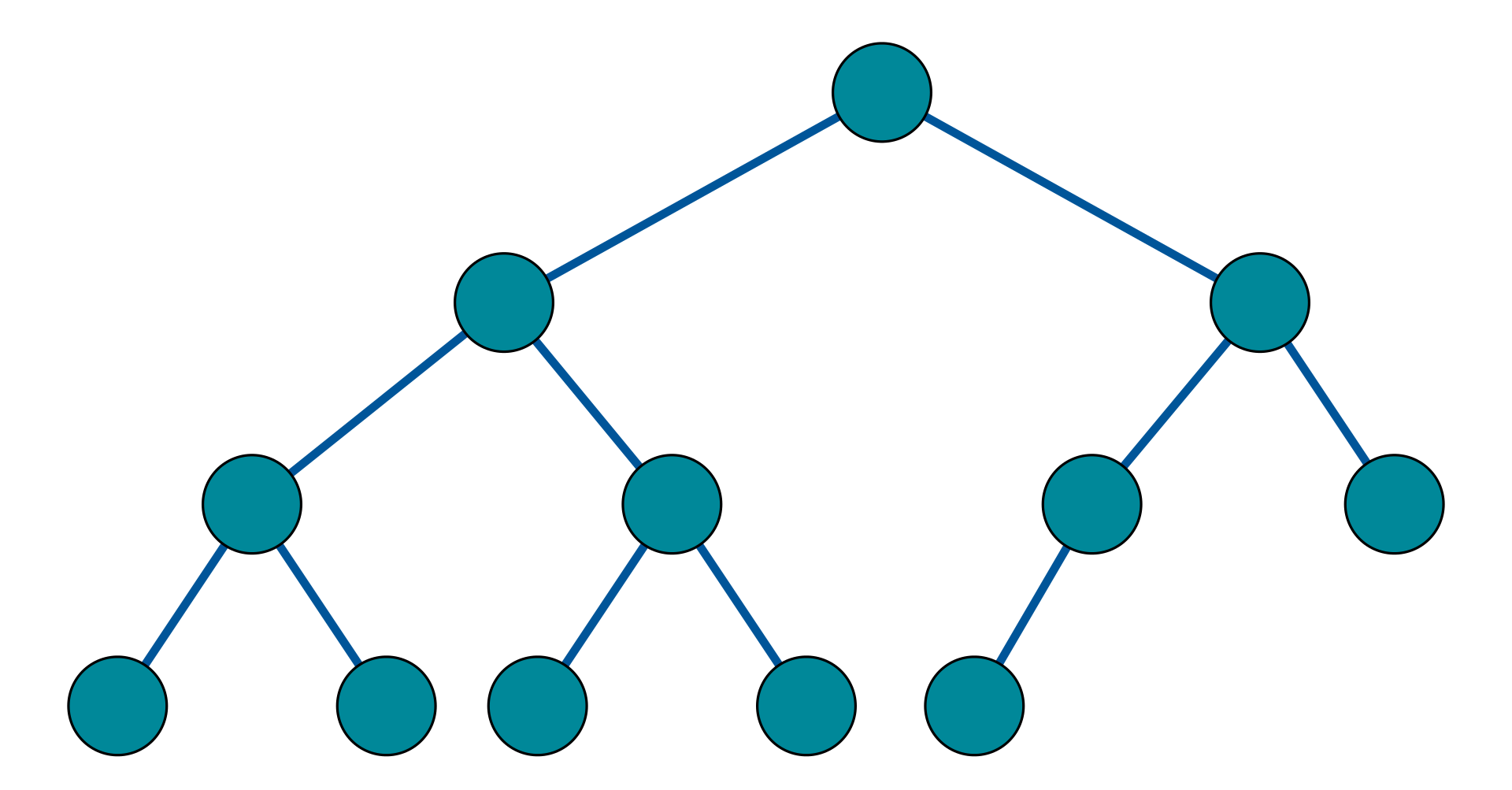
Balanced
Where left and rigt subtrees of every node differ in height by at most 1. i.e. where no leaf is much farther away from the root than any other leaf.
Properties
Level of a tree is a set of nodes at the same depth.
So in a binary tree, level 0 has at most 1 node. Level 1 has at most 2 nodes. Level 2 has at most 4 nodes etc.
So in general, a level d has at most \(2^d\) nodes.
Therefore from this we can see that the number of nodes at any given level is exponential. From this we can define the following properties where - \(n_E\) is number of external nodes, \(n_I\) is the number of internal nodes, \(n\) is the numberof nodes, and \(h\) is the height of the tree:
- \(h + 1 \leq n \leq 2^{h+1}-1\)
- \(1 \leq n_E \leq 2^h\)
- \(h \leq n_I \leq 2^h - 1\)
- \(log(n+1) - 1 \leq h \leq n - 1\)
Also if the tree is proper then:
- \(2h + 1 \leq n \leq w^{h+1} - 1\)
- \(h + 1 \leq n_E \leq 2^h\)
- \(h \leq n_I \leq 2^h - 1\)
- \(log(n+1) - 1 \leq h \leq (n-1)/2\)
- \(n_E = n_I + 1\)
For reference, \(n_E\) = external nodes = nodes with no children. \(n_I\) = internal nodes = nodes which are not leaves.
Array Based Binary Tree
1 2 3 4 5 6 7 8 9 10 11 | |
BFS or level numbering of positions to build an array is fairly common. Here a position can be represented by a single integer - the main advantage of this data structure. But operations like deleting and promoting children takes O(n) time.
Utilizing the General Tree Linked Structure
For a binary tree the children are defined as left and right child.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 | |
Tree Traversal Algorithms
Go to Algorithms >> Tree Traversals
We can also modify our base Tree class to implement the traversal methods as well, with the pre-order traversal being the default one.
Refer to Tree Abstract Base Class for the other parts of the base class.
Some key observations:
- we implement the traversals as generator functions where we yield each position to the caller and let the caller decide what action to perform at that position
- the
positionsmethod returns the iteration as an object - again acting as a generator - the
breadth first searchorbfstraversal is iterative - not recursive - the
inordertraversal is only implemented forbinary trees- it does not generalize for generic trees
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 | |
As can be seen, while we can implement specific traversals for the Tree class, or the inorder method for binary trees, the code is not general enough to capture the range of computations possible. These were all custom implementations with some repeating algorithmic patterns (e.g. blending of work performed before or after recursion of subtrees).
A more general framework for implemting tree traversals is through Euler tour traversals which also uses the Template method.
Binary Search Trees
If we have a set of unique elements that have an order relation (e.g. a set of integers), we can construct a binary search tree such that for each position p of the tree T:
- Position
pstores an element of the set, denoted ase(p) - Elements stored in the left subtree of
p(if any) are less thane(p) - Elements stored in the right subtree of
p(if any) are greater thane(p)
Binary Search Trees can be used to efficiently implement a sorted map - assuming we have an order relation defined on the keys.
Navigating Binary Search Trees
An inorder traversal of a binary search tree visits positions in increasing order of their keys. Therefore if presented with a binary search tree, we can produce a sorted iteration of the keys of a map in linear time.
Hence binary search trees provide a way to produce ordered data in linear time.
Additionally binary search trees can be used to find:
- position containing the greatest key that is less than the position
p- the position that would be visited immediately before positionpin an inorder traversal - position containing the least key that is great than the position
p- the position that would be visited immediately after positionpin an inorder traversal
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | |
Searches
We can traverse a binary search tree to search for specific keys in O(log(n)) time complexty as long as it is balanced. In the worst (imbalanced) case the height h of the tree can be equal to the n in which case the time complexity would be O(h) = O(n) instead.
1 2 3 4 5 6 7 8 | |
Insertions
Search for key k, and if found, that item's existing value is reassigned. If not found, a new item is inserted into the underlying tree T in place of theempty subtree that was reached at the end of the fialed search.
1 2 3 4 5 6 7 8 9 | |
This is always enacted at the bottom of a path.
O(h)
Deletions
More complicated than insertions as they can happen in any part of the tree.
Steps:
- If key k is successfully found in tree T:
- if p has at most one child, delete item with key k at position p, and reoplace it with its child
- if p has two children: locate the predecessor (the rightmost position of the left subtree of p) i.e. r = before(p), then use r as replace for the position p, and then delete r (simple as it does not have a right child by defition)
O(h)
Python Implementation
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 278 279 280 281 282 283 284 285 286 287 288 289 290 291 292 293 294 295 296 297 298 299 300 301 302 303 304 305 306 307 308 309 310 311 312 313 314 315 316 317 318 319 320 321 322 323 324 325 326 327 328 329 | |
Self Balancing Trees
Some sequences of operations on binary search trees may lead to an unbalanced tree with height proportional to n. Hence we may only claim O(n) search.
However there are common search tree algorthms that provide stronger performance guarantees. AVL, Splay and Red-Black trees are based on augmenting the standard binary search tree with occasional operations to reshape the tree and reduce its height.
The primary operation to rebalance a binary search tree is known as a rotation. During a rotation, we "rotate" a child to be above its parent, as diagrammed below:
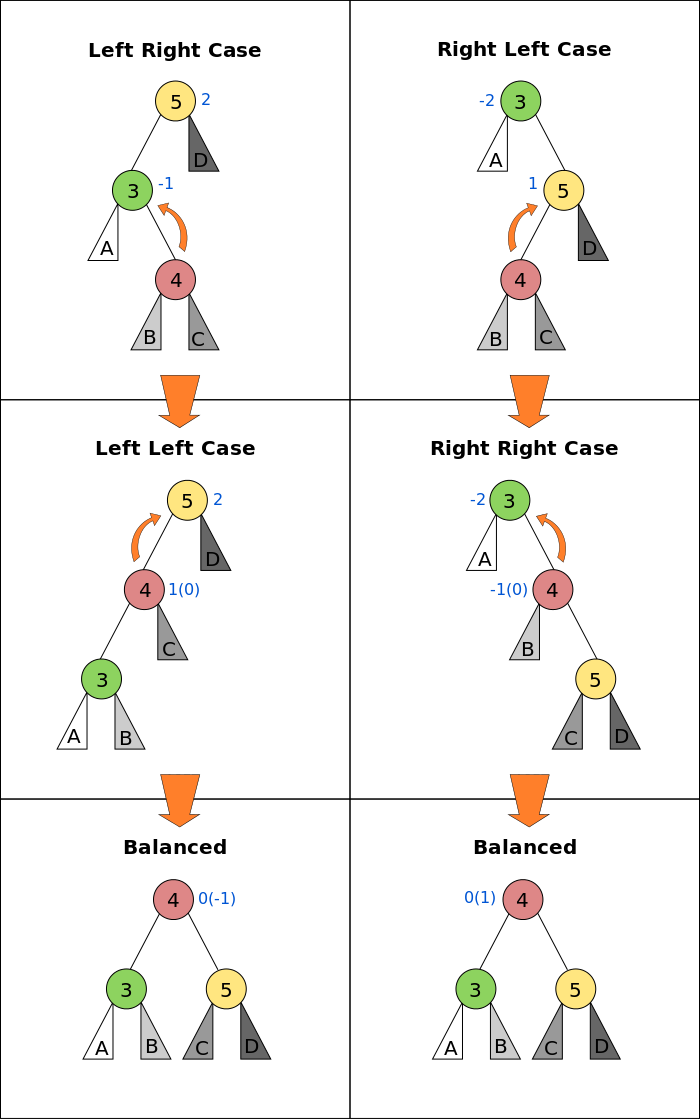
There are two primary types of rotations: left rotations and right rotations. Both types are used to adjust the structure of the tree without violating the binary search tree properties, where the left child of a node is less than the node, and the right child is greater.
Right Rotation
A right rotation is performed on a node that has a left child. This operation shifts the node down to the right, making its left child the new parent of the subtree. Here's how it works:
- Given a node
Xwith a left childY,Ywill become the new root of the subtree. X's left subtree becomesY's right subtree.Ytakes the place ofX, andXbecomes the right child ofY.
This operation is used when the tree becomes left-heavy, and we need to decrease the height of the left subtree to maintain balance.
Left Rotation
A left rotation is the mirror operation of a right rotation. It is performed on a node that has a right child, shifting the node down to the left and making its right child the new parent of the subtree. Here's the step-by-step process:
- Given a node
Xwith a right childY,Ywill become the new root of the subtree. X's right subtree becomesY's left subtree.Ytakes the place ofX, andXbecomes the left child ofY.
This operation is used when the tree becomes right-heavy, and we need to decrease the height of the right subtree.
Visual Representation
Let's illustrate both rotations with diagrams. For a right rotation:
1 2 3 4 5 | |
1 2 3 4 5 6 7 8 9 10 11 | |
and for a left rotation:
1 2 3 4 5 | |
1 2 3 4 5 | |
AVL Trees
AVL Trees store a balance factor on each node that follows the height balance property where for each position p of T, th heights of the children of p differ at most by 1.
The height is defined as the longest path from the node to a leaf.
Hence the subtree of an AVL tree is itself an AVL tree. The height of an AVL tree storing n entries is O(logn).
The insertion and deletion operations of AVL trees begin similarly to the corresponding operations for binary search trees, but with post-processing for each oepration to restore the balance of ay portions of the tree that are adversely affected by the change.
Insertion in AVL Trees
Insertion into an AVL tree involves several steps:
- BST Insertion: The node is inserted following the binary search tree rules.
- Updating Heights: After insertion, the heights of the ancestors of the inserted node are updated.
- Balancing the Tree: If any ancestor node becomes unbalanced (balance factor is not -1, 0, or 1), rotations are performed to balance the tree.
Rotations for Rebalancing
Depending on the structure of the tree at the unbalanced node, one of the following rotations is performed:
- Single Right Rotation (LL Rotation): When the left subtree of the left child is causing the imbalance.
- Single Left Rotation (RR Rotation): When the right subtree of the right child is causing the imbalance.
- Left-Right Rotation (LR Rotation): When the right subtree of the left child is causing the imbalance.
- Right-Left Rotation (RL Rotation): When the left subtree of the right child is causing the imbalance.
Deletion in AVL Trees
Deletion from an AVL tree is a bit more complex:
- Node Removal: Follows the basic BST deletion rules.
- Balancing the Tree: After deletion, the tree might become unbalanced. The same procedure of updating heights and performing rotations is followed to restore balance.
Performance of AVL Trees
- Search: \(O(\log n)\) - AVL trees ensure that the height of the tree is always logarithmic in the number of nodes, guaranteeing efficient searches.
- Insertion: \(O(\log n)\) - Insertions may require a constant number of rotations, but the overall time complexity remains logarithmic.
- Deletion: \(O(\log n)\) - Similar to insertion, deletions are logarithmic in time complexity, including potential rotations for rebalancing.
Red-Black Trees
A Red-Black tree is characterized by several key properties:
- Node Color: Each node is colored either red or black.
- Root Property: The root node is always black.
- Red Node Property: Red nodes cannot have red children. This means no two red nodes can be adjacent.
- Black Height Property: Every path from a node to its descendant NULL nodes must contain the same number of black nodes. This consistent count of black nodes is known as the black height.
- New Nodes are Red: Newly inserted nodes are always colored red. This helps maintain the black height property with fewer rotations.
Insertion
Inserting a new node into a Red-Black tree involves several steps:
- BST Insertion: Initially, the node is inserted according to the rules of a binary search tree (BST), based on key comparisons.
- Coloring: The new node is colored red.
- Rebalancing: The tree is adjusted to maintain the Red-Black properties through recoloring and rotations.
The rebalancing phase takes into account various cases depending on the color of the uncle node (the sibling of the new node's parent) and the structure of the tree, aiming to fix any violations of the Red-Black properties.
Deletion
Deletion in a Red-Black tree is more complex due to the balancing properties:
- Node Removal: Follows the BST deletion rules. If the node to be deleted has two children, it's replaced with its in-order successor or predecessor, which is then deleted.
- Rebalancing: If a black node was deleted or replaced, the tree might need to be rebalanced to maintain the black height.
Rebalancing after deletion also considers several cases, focusing on the color of the sibling of the node being fixed and the color of the sibling's children.
Rotations
Rotations help maintain or restore Red-Black properties during insertions and deletions:
- Left Rotation: Performed when the tree is too heavy on the right, rotating a parent node to the left around its right child.
- Right Rotation: Used when the tree is too heavy on the left, rotating a parent node to the right around its left child.
Performance
Operations such as search, insertion, and deletion in Red-Black trees have a time complexity of \(O(\log n)\), where \(n\) is the number of nodes. This efficiency is due to the tree's self-balancing nature, ensuring operations remain fast.
Python Implementation
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 | |
Splay Trees
Splay trees are a type of self-adjusting binary search tree with the unique property that recently accessed elements are moved to the root of the tree using a process called splaying. This makes frequently accessed elements quicker to access again in the future.
Key Characteristics
Unlike traditional binary search trees, splay trees do not maintain strict balance. Instead, they perform a series of rotations (splays) to move an accessed node to the root. This adaptive strategy optimizes the tree's structure based on usage patterns, often providing better performance for sequences of non-random operations.
Splaying Operations
Splaying involves performing rotations on a node until it becomes the root of the tree. There are several types of splay operations, depending on the position of the node and its parents:
- Zig: A single rotation is used when the node is a direct child of the root.
- Zig-Zig: A double rotation is used when both the node and its parent are either left children or right children.
- Zig-Zag: A double rotation of different types (first right then left, or first left then right) is used when the node is a right child and its parent is a left child, or vice versa.
Insertion in Splay Trees
Insertion in a splay tree follows these steps:
- Insert the new node: First, insert the new node using the standard binary search tree insertion procedure.
- Splay the node: After insertion, splay the inserted node, moving it to the root of the tree.
Deletion in Splay Trees
Deletion in a splay tree involves:
- Splay the node: First, splay the node to be deleted, bringing it to the root of the tree.
- Remove the node: If the node has two children, replace it with its successor or predecessor, then splay that node to the root and remove the original node. If it has one or no children, simply remove it as in a BST.
Searching in Splay Trees
To search for a value in a splay tree:
- Perform standard BST search: Find the node containing the value.
- Splay the node: Whether found or not, splay the last accessed node to the root.
Performance of Splay Trees
The performance of splay trees is not strictly \(O(\log n)\) for individual operations. However, they offer amortized \(O(\log n)\) performance over a sequence of operations due to the self-adjusting nature of splaying. This makes them particularly effective for applications with non-uniform access patterns.
(2,4) Trees
(2,4) trees, also known as 2-4 trees, are a type of balanced tree data structure that provides an efficient way to manage and search for data. They are a special case of B-trees and are particularly useful in databases and filesystems.
Key Characteristics
- Node Capacity: Each node in a (2,4) tree can have between 2 and 4 children, and accordingly, 1 to 3 keys.
- Balanced Height: All leaves are at the same depth, which ensures that operations are performed in logarithmic time.
- Flexible Node Configuration: The ability to have a variable number of children and keys allows (2,4) trees to remain balanced with a minimal number of tree rotations and rebalancing.
Operations in (2,4) Trees
Insertion
When inserting a new key into a (2,4) tree: 1. Find the correct leaf node where the key should be inserted, following standard tree search procedures. 2. Insert the key into the node. - If the node has fewer than 3 keys, simply add the new key. - If the node already contains 3 keys, it is split into two nodes, each with fewer keys, and the middle key is moved up to the parent. This process may propagate up the tree.
Deletion
Deletion from a (2,4) tree involves: 1. Locating the key to be deleted. 2. Removing the key and rebalancing the tree. - If removing the key would leave a node with fewer than 1 key, keys or nodes are redistributed to maintain the tree's balance. This might involve borrowing a key from a sibling node or merging with a sibling if both have the minimum number of keys.
Searching
Searching for a key in a (2,4) tree follows the basic principles of binary search within the keys of each visited node and choosing the appropriate child to continue the search based on the comparison.
Balancing and Performance
- Balancing: (2,4) trees are self-balancing, with each operation ensuring that the tree remains balanced, thus maintaining its performance guarantees.
- Performance: The operations of search, insertion, and deletion in a (2,4) tree all have a worst-case time complexity of \(O(\log n)\), where \(n\) is the number of keys in the tree.
Segment Trees
TODO: Add notes here - leaving blank for now.
Fenwick Trees
TODO: Add notes here - leaving blank for now.
References
-
Skiena, Steven S.. (2008). The Algorithm Design Manual, 2nd ed. (2). : Springer Publishing Company. ↩
-
Goodrich, M. T., Tamassia, R., & Goldwasser, M. H. (2013). Data Structures and Algorithms in Python (1st ed.). Wiley Publishing. ↩
-
Cormen, T. H., Leiserson, C. E., & Rivest, R. L. (1990). Introduction to algorithms. Cambridge, Mass. : New York, MIT Press. ↩